Discussion Modèle:Lang
Un article de Wikipédia, l'encyclopédie libre.
Sommaire |
[modifier] Italique
Il faudrait créer un doublon de ce modèle pour les langues n'utilisant pas l'alphabet latin : en effet, il ne faut dans ce cas là pas mettre le texte étrangerophone en italique. R@vən 1 décembre 2006 à 00:16 (CET)
- Il ne faut jamais mettre le texte en italique : l'indication de langue prévaut sur cette règle de typographie française. On peut ensuite directement définir des règles CSS pour mettre les textes latin non français en italique, mais je ne pense pas que ce soit vraiment utile. Gentil ♡ 9 décembre 2006 à 22:51 (CET)
- Hmm, pourquoi cela prévaut-il ? À mon humble avis, il serait souhaitable qu'il y ait une cohérence entre ce template et la recommandation de Wikipédia:Conventions typographiques#Mots étrangers: « Les noms communs étrangers, c'est-à-dire ceux qui ne sont pas entrés dans le vocabulaire français et sont donc absents des dictionnaires du français usuel, sont toujours en italique lorsqu'ils sont écrits avec l'alphabet usuel (dit alphabet latin moderne) ou ses variantes. ».
- Ensuite, que ce soit géré par les CSS par défaut ou par l'ajout de guillemets, peu importe, tant que c'est homogène. Ce`dric 19 janvier 2007 à 19:34 (CET)
- Attention, de tels termes ne doivent pas être employés avec {{lang}}, car la phrase qui contient un terme d'origine étrangère reste une phrase en français. Gentil ♡ 20 janvier 2007 à 12:50 (CET)
- Ok, donc l'usage de ce modèle concerne uniquement des textes ou expressions complètes, autonomes, et non pas des mots isolés.
- Non, j'ai dit que ce modèle ne concerne pas les termes au sein de phrases en français. Les termes isolés, servant eux à une étymologie ou une traduction, doivent être identifiés par le modèle. Gentil ♡ 20 janvier 2007 à 17:35 (CET)
- Ma confusion vient du fait qu'on le voit souvent utilisé pour de simples mots, en général pour définir l'orthographe d'un mot dans une autre langue en parallèle de l'orthographe francisée. Ou alors par le biais de {{grec ancien}}, pour donner l'étymologie d'un mot (bien qu'évidemment ici la question de l'italique ne se pose pas).
- Par exemple dans Kalevala on trouve « Le Kalevala est composé de cinquante chants (le mot finnois, ''{{lang|fi|runo}}'', est souvent traduit par ''rune'', mais a seulement à faire indirectement avec les signes runiques du vieux germanique). ». L'usage de ce modèle est-il légitime dans ce cas ?
- Qu'en est il d'un mot donné entre parenthèses parcequ'il n'existe pas d'équivalent en français, généralement pour des raisons culturelles ? Par exemple « Parfois voit-on aussi des « garçons étoilés » (stjärngossar) lors de la Sainte Lucie ». Ce`dric 20 janvier 2007 à 14:35 (CET)
- Oui, pour tout ce qui est étymologie, ce modèle est bien employé. Donc tes exemples méritent l'utilisation du modèle. Je vais grossir un exemple où il ne faut pas l'employer : « Les internautes downloadent souvent des animes sur peer-to-peer. » Ici, les termes d'origine étrangère ne sont pas des explications lexicales, mais des mots étrangers employés abusivement en français. L'italique s'impose, mais pas le modèle. Gentil ♡ 20 janvier 2007 à 17:31 (CET)
- Ok, donc l'usage de ce modèle concerne uniquement des textes ou expressions complètes, autonomes, et non pas des mots isolés.
- Attention, de tels termes ne doivent pas être employés avec {{lang}}, car la phrase qui contient un terme d'origine étrangère reste une phrase en français. Gentil ♡ 20 janvier 2007 à 12:50 (CET)
[modifier] Marche pas
Ce modèle ne marche pas si on ecrit juste {{lang|rtl|ar| 'mot'}} . Il faut absolument ajouter la balise 'code' comme ça <code> {{lang|rtl|ar| 'mot'}} </code> pour qu'il s'active .On m'a dit que la balise code s'utilise pour la programmation, par pour quoté une langue. Où est donc le problème? Mokaaa??? يا أخي إسآل 11 février 2007 à 17:57 (CET)
- De quoi parles-tu ? Où ne fonctionne-t-il pas ? Normalement, on n'utilise jamais <code> avec ce modèle. Gentil ♡ 12 février 2007 à 01:24 (CET)
- Ok, je vois la différence dont tu parles. Pour moi, voici l'aspect de ta page utilisateur :
-
 arabe avec Microsoft sans serif
arabe avec Microsoft sans serif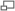
- Mais pour les visiteurs, l'aspect est celui-ci :
-
 arabe sans Microsoft sans serif
arabe sans Microsoft sans serif - La balise <code> impose simplement une largeur fixe à tout texte qu'elle contient. Si tu désires le même effet pour l'arabe, alors il suffit d'imposer la police de caractères adaptée pour l'arabe. Tu peux le faire dans ton propre Special:MyPage/monobook.css, en prenant exemple sur le mien et en employant la classe .lang-ar, ou bien on peut généraliser l'apparence de l'arabe à tous les visiteurs en faisant une demande à un administrateur. Gentil ♡ 12 février 2007 à 01:44 (CET)
Effectivement, ce qui apparait chez moi est le deuxième screenshot que tu as mis. Vous serez d'accord avec moi que la police de la première ligne est plus lisible que celle de la seconde. C'est pour ça que le jour où j'avais ajouté la balise code j'ai aimé le rendu... Bon, là vous dites que cette balise code n'est pas faite pour ça, ok, ce n'est pas grave. Concernant le 1èr screenshot, le fait que ça soit en gras améliore un peu la lisibilité, mais bon ça reste toujours serré, et puis mettre les caractères en gras ne serait pas très judicieux dans les articles. L'interet pour moi est de permettre une bonne lisibilité au lecteur lambda, pas pour moi. Parceque là, je vois pas trop l'interet du modèle? si meme sans l'utiliser, on a le meme rendu!? N'est il pas possible d'espacer ou d'agrandir un peu les caractères? Par exemple, de le rendre un peu comme l'ecriture en Persan sur la première ligne de cet article here. C'est pas très beau mais au moins nettement plus visible. Merci Mokaaa??? يا أخي إسآل 12 février 2007 à 13:27 (CET)
[modifier] Problème des translittérations, romanisations et autres transcriptions
En effet, comment distinguer les kanji et les kana (hiragana & katakana) du romaji ? Il n'existe que le code ja correspondant à la langue japonaise. Idem pour les hànzì et les pīnyīn ! Le problème se posent pour toutes les langues n'utilisant pas l'alphabet latin et possédant donc une transcription en alphabet latin. En soit ce n'est pas bloquant mais c'est gênant dans le cas où comme moi, je spécifie une taille 200 % pour les sinogrammes et kanji/kana ! Quelqu'un a une solution ? une idée ? VIGNERON * discut. 27 mai 2007 à 12:29 (CEST)
- Voir le modèle anglais en:Template:Transl, qui est susceptible, à défaut d'apporter des éléments de réponse, de fournir des pistes de réflexion, puisque certaines des translittérations suivent une codification internationale stricte. Pour ma part, avec le modèle français, j'ai déjà utilisé concurremment {{lang|sr|sr-Cyrl}} et {{lang|sr|sr-Latn}} puisque les doubles codes langue+alphabet sont censés être reconnus par les navigateurs oraux, selon la spécification HTML. Ton problème est peut-être toutefois un peu plus compliqué que celui que j'ai eu à résoudre lorsqu'il m'est arrivé de vouloir écrire du serbe selon les deux graphies. Hégésippe | ±Θ± 3 juin 2007 à 21:07 (CEST)
[modifier] Proposition d'amélioration de modèle
J'étais assez chagriné de voir les modifs de Modèle:MyBot sur le modèle {{persan}}, car le modèle remplacé ne fait pas la même chose et qu'il va falloir se retaper du texte plutôt que de se servir du modèle qui fait tout... En bref, je souhaiterais qu'on puisse réfléchir à un modèle commun qui serve à mettre le texte dans une langue étrangère ainsi qu'une translitération, en paramétrant la langue. Ce modèle pourrait être de la forme {{Translit|fa|زمانی برای مستی اسبها|Zamāni barāye masti-ye asbhā}} qui donnerait (en [[persan]] : {{lang|rtl|fa|زمانی برای مستی اسبها}}, ''Zamāni barāye masti-ye asbhā''}}, soit (en persan : زمانی برای مستی اسبها, Zamāni barāye masti-ye asbhā). On peut alors le paramétrer avec toutes les langues. Je peux avoir des avis ? فاب - so‘hbət - 15 juin 2007 à 10:11 (CEST)
- J'avais utilisé le modèle modèle:persan jusqu'au jour où je l'ai vu qualifier d'obsolète avec pour recommandation d'utiliser le modèle:lang, ça date d'au moins deux ans... MyBot à le réflexe tardif et inversé M.B. 15 juin 2007 à 17:21 (CEST)
- Peut-être des paramètres nommés, plutôt que positionnels? {{Translit|lang=fa|text=زمانی برای مستی اسبها|alt=Zamāni barāye masti-ye asbhā}} Ugo14 18 juin 2007 à 09:12 (CEST)
- En utilisant {{{text|{{{1}}}}}} pour compatibilité ascendante, pas bête. (Autrement dit, cela autorise d'utiliser soit {{lang|fa|text=زمانی برای مستی اسبها}}, soit {{lang|fa|زمانی برای مستی اسبها}} comme avant.)
- Peut-être des paramètres nommés, plutôt que positionnels? {{Translit|lang=fa|text=زمانی برای مستی اسبها|alt=Zamāni barāye masti-ye asbhā}} Ugo14 18 juin 2007 à 09:12 (CEST)
Que pensez-vous de Utilisateur:Lachaume/Lang ? Par ailleurs, ne pourrait-on pas automatiser l'ajout de la directionnalité grâce à un modèle {{dir|code langue}} ? — Régis Lachaume ✍ 19 juin 2007 à 18:01 (CEST)
Autres idées :
Ne faudrait-il pas ajouter un espace entre le mot écrit dans la langue et son éventuelle translitération ?
De plus ne serait-il pas judicieux d'ajouter un title= qui affiche le mot "translitération" lorsqu'on passe la souris sur le mot indiqué en paramètre trans= (ou alt= avec le modèle translit s'il existe encore) ?
— MetalGearLiquid [m'écrire] 25 décembre 2007 à 03:43 (CET)
[modifier] Quel code langue ?
Pour le tibétain on prend l'ISO 639-1 bo ou l'ISO 639-2 tib (B) / bod (T) (quelle différence ?) ou bien l'ISO/DIS 639-3 bod ? VIGNERON * discut. 17 juin 2007 à 13:49 (CEST)
- Je viens de regarder dans la liste IANA et je trouve deux occurrences de Tibetan :
bode type language etTibtde type script. Je suppose que ce que le code à utiliser estbomais j'aimerais bien connaître la différence. VIGNERON * discut. 25 août 2007 à 10:09 (CEST)
[modifier] Italique et arabe
L'arabe en italique devient illisible, et « c'est pas bien » M.B. (d) 29 mars 2008 à 15:05 (CET)
- Zut :). Je vais essayer d'améliorer le code pour que les langues à caractères latins soient en italique et les autres dans leur format d'origine. PoppyYou're welcome 29 mars 2008 à 15:23 (CET)
- Pb d'affichage également pour le cyrillique. Avant de faire joujou avec les modèles, il serait bon de se préoccuper des conséquences... Je rajoute également que la mise en forme typographique ne doit pas être "codée" dans les modèles mais laissée à l'initiative de l'utilisateur du modèle. H2O (d) 29 mars 2008 à 18:47 (CET)
[modifier] Espace manquante
Une petite erreur à corriger sur {{Lang}}, il manque une espace entre le texte et la parenthèse de sa translittération (ce qui n'est peut-être pas très visible sur l'exemple japonais, mais le devient beaucoup plus avec du grec ou du russe) :
- Exemple :
{{lang|el|texte=ἡμερα|trans=êméra}} - Donne : ἡμερα (êméra)
Pour la correction, l'espace ne peut être ajouté que s'il y a effectivement une parenthèse (donc il faut un test #if) et il vaut probablement mieux ne pas utiliser une espace insécable (ça risquerait de créer un segment très long dans certains cas, et ça n'est pas anormal qu'une parenthèse soit à la ligne suivante), donc je crois qu'il faudrait :
- Remplacer ce bout : {{{trans|}}}
- Par celui-ci :
{{#if:{{{trans|}}}|<!--espace normale--> {{{trans|}}}}}
(Je poste ça ici pour archive, et je lance une Wikipédia:Demande d'intervention sur une page protégée identique.) — Babinski (Discutski) 3 avril 2008 à 20:06 (CEST)
- L'utilisation d'un commentaire avant l'espace ne marche pas pour empêcher que cette espace soit supprimée du paramètre. En effet, lors que les paramètres de modèles (ou des fonctions du parser comme ici #if) sont évalués, les commentaires HTML sont supprimés directement (en fait ils le sont très tôt, dès la lecture du code wiki n’importe queller page ou modèle à inclure), puis les espaces sont compressés.
- La solution c’est d’insérer un
<nowiki/>vierge avant cette espace :{{#if:{{{trans|}}}|<nowiki/> {{{trans|}}}}}
- En effet les sections marquées par nowiki sont conservées durant toute l’expansion des modèles, et ces balises de marquage nowiki (balises de début ou de fin de section ou même vides) sont enlevées seulement à la fin, lors de la traduction en HTML du code wiki étendu final...
- Durant toute l’évaluation des paramètres et l'expansion des modèles, les balises nowiki sont traitées comme s’il s'agissait de texte normal (et donc les espaces avant ou après sont traités comme ceux séparant des mots: ils peuvent être compressés mais pas totalement supprimés).
- L’astuce vaut aussi pour conserver un saut de ligne au début d'un paramètre notamment pour la mise en forme de tbleaux contenant des rangées ou cellules conditionnelles): on met un
<nowiki/>juste avant un saut de ligne à conserver en début de paramètre, ou juste après un saut de ligne à conserver en fin de paramètre. Verdy p (d) 14 juin 2008 à 22:35 (CEST) - Note: la solution actuellemet employées utilise pour cette espace une entité XML/HMTL " " ça marche depuis peu de temps pour éviter que cette espace soit supprimée, mais pas encore sur toutes les versions de MediaWiki, et cela reste instable car c'est génant dans l'évaluation de certaines expressions comme les tests de nullité (avec le premier paramètre de #if), ou tests d’égalité (dans les deux premiers paramètres de #ifeq ou les case d'un #switch avant le signe "=") ou encore dans les expressions, car ces entités sont converties en caractères normaux (et parfois alors compressés à nouveau) avant d’évaluer le test de nullité ou d’égalité ou d’évaluer l’expression (note: dans les expressions numériques avec #expr ou #ifexpr, les blancs ne nécessitent aucun traitement car ils n’y ont jamais aucune valeur, ils peuvent toujours être supprimés et donc il ne faut pas mettre de balises nowiki dedans sinon l’expression ne s’évaluera pas correctement).
- C’est une partie assez instable du traitement du code wiki qui varie encore d’une version à l’autre de MediaWiki. La gestion des blancs a toujours été assez compliquée en MediaWiki. Verdy p (d) 14 juin 2008 à 22:54 (CEST)

